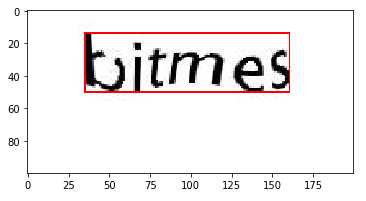
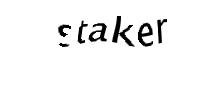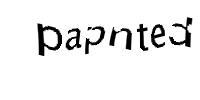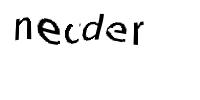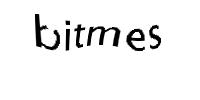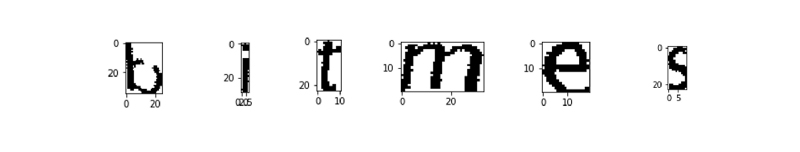The task was to train machine learning models from a given sample of Captcha images so as to decode and identify characters from similar test Captchas. Images similar to following pattern were used for this task:
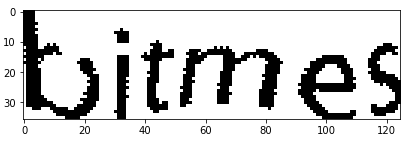
The original image was RGB, so the first task was to convert captcha images into Greyscale so as to make image processing task easier.
Next step was to identify ROI (Region Of Interest). The captcha image consisted of unwanted white space which was to be removed so as to focus only on the required region and apply image processing steps with more ease. The bounded region was then cropped out.
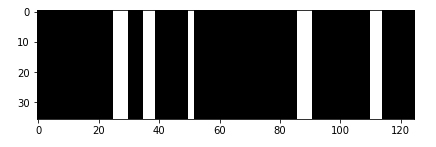
Having got the cropped image, the individual characters needed to be cropped out, the most challenging part of the project. For first iteration, a simple algorithm was used to separate the characters as shown below
The cropped image was segmented along the white lines as shown above to extract the individual characters as shown below
Each character obtained is going to be a data point in the final training dataset. Therefore the next step was to extract features from these training images. Following features were extracted from dataset :
1.Width 2.Height 3.Aspect ratio 4.Vertical symmetry 5.Horizontal symmetry 6.X Histogram 7.Y Histogram 8.White pixels 9.Black pixels
The final dataset consisted of 141 datapoints (datapoint = each extracted character) where each of them consisted of 57 features and a character-to-numeric mapped label. Once the data was ready, SVM and Random Forest classifiers from Sklearn were trained and used to predict the test image